We Build Enterprise Conversational AI Agents That Talk to Your Data — and We've Already Shipped Two
- 1 day ago
- 4 min read
Somewhere in your organisation, the answer already exists.
It's in a contract, a spreadsheet, a project system, a 4,000-page archive, a database three teams away. Your people know it's there. They just can't get to it without opening the right dashboard, knowing the right filter, or asking the right colleague to stop their work and pull it.
That's not a small inconvenience. Databricks estimates that roughly 80% of enterprise knowledge stays locked in unstructured documents that conventional systems can't read or reason over. The data is stored. It just isn't usable.
At VigaET, we close that gap. We engineer enterprise conversational AI agents — software your team can simply ask, that answers instantly from your live data, securely and in context.
This is not a pitch for a roadmap. We have already designed, optimised and deployed these systems — in two industries that could not be more different. This article is how we build them, why most attempts fail, and what it means if you're weighing the same move for your own company.
The real problem was never AI. It was access.
For decades, the enterprise answer to "we have too much data" was to store it better — more dashboards, more BI tools, more document management. Useful, but it left the hard part untouched: every one of those interfaces assumes the user already knows where to look and what to ask for.
So the real workflow looked like this: hunt across silos, raise a ticket to the data team, wait, and receive a static export that's already going stale. The information was there. Reaching it cost hours.
The shift we engineer for is simple to say and hard to build: move from storing data to conversing with it.

What we actually build
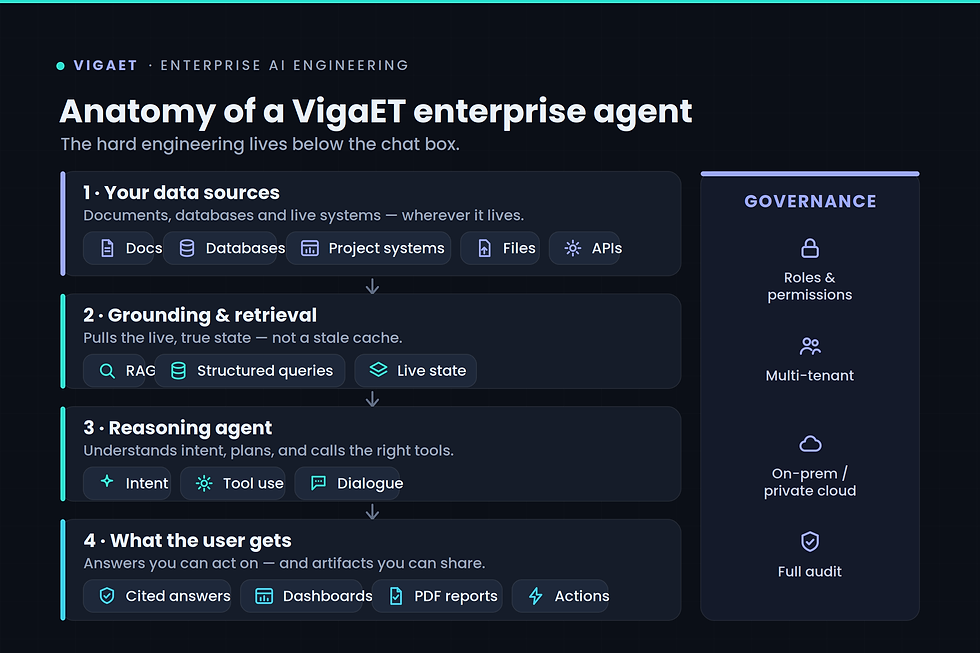
An enterprise conversational AI agent is not a chatbot bolted onto a search bar. It's a system that understands your domain, connects to your real data, and acts on it. The agents VigaET builds can:
Query your live data — answering from what's true right now, not a stale export
Render interactive artifacts — dashboards, charts, kanban boards and tables, generated on demand
Produce reports — formatted, shareable documents in seconds
Understand the files you give it — reading PDFs, spreadsheets and images as context
Respect roles and permissions — so each person sees only what they should
Deploy the way you need — on-premises, in your private cloud, or fully managed

Why most "chat over your data" projects fail
Putting a chat box in front of a database takes a weekend. Making it trustworthy on real enterprise data is where almost everyone stalls — and it's where our engineering actually lives.
Four problems decide whether one of these systems survives contact with production:
Grounding. An agent that answers from a model's memory will confidently make things up. Ours are grounded in your live, structured data — using retrieval-based techniques so every answer traces back to a real source, not a guess.
Live state. It has to read what's true now, not a nightly cache.
Governance. Roles, permissions, multi-tenancy and audit have to run through every layer — not be sprinkled on at the end.
Scale and responsiveness. Real workloads mean hundreds of thousands of records and many concurrent users, with answers that stream back in real time instead of hanging on a spinner.
The reason this is hard is also the reason it's defensible. Industry leaders building enterprise retrieval systems are converging on exactly these foundations — and they're the foundations we've already built and shipped.
Proof, not slides
We didn't validate any of this in a sandbox. We have two enterprise conversational AI systems live, in two very different domains.
Construction — document intelligence at scale. We built an on-premises agent over a corpus of roughly 400,000 files, so teams could ask the archive a question and get a precise, grounded answer instead of digging through folders for hours. (Read the full story: VigaET construction document-intelligence case study.)
Film & VFX — the Moviecolab production assistant. Inside our own production platform, we shipped a role-aware and phase-aware assistant that queries live project data, renders dashboards and reports, and adapts to who's asking. It ran a full production — distributed team, hundreds of tasks — end to end. (Deep dive: How we built the Moviecolab production assistant.)
Two industries. One engineering core. That's the point: the hard parts — grounding, governance, scale, deployment — transfer. The domain on top is yours.

Enterprise-grade by design
When the system holds your company's knowledge, "it mostly works" isn't good enough. Every agent we build is engineered around four non-negotiables:
Grounded — answers come from your data, with sources, not invention
Governed — roles, permissions and a full audit trail
Private — runs on-premises or inside your VPC; your data never has to leave
Scalable — multi-tenant, real-time, built for production load

If your data should be answering questions, let's build the enterprise conversational AI agents
The companies that win the next few years won't be the ones with the most data. They'll be the ones whose people can actually reach it — by asking, in plain language, and getting a trustworthy answer back.
That's the system we build. We've proven it in construction and in film, and we engineer it with the grounding, governance and scale that enterprise work demands.
If your organisation's knowledge is sitting in storage when it should be answering questions, that's exactly the problem VigaET solves.
VigaET (Viga Entertainment Technology) is an enterprise AI and real-time systems company. We build grounded, governed conversational AI agents and intelligent data systems for organisations that need their knowledge to be usable — not just stored.



Comments